您现在的位置是:网站首页 -> 代码相关 文章内容
makefile 自动处理头文件的依赖关系-itarticl.cc-IT技术类文章记录&分享
发布时间: 9年前【代码相关】 247人已围观【返回】
现在我们的Makefile写成这样:
all: main
main: main.o stack.o maze.o
gcc $^ -o $@
main.o: main.h stack.h maze.h
stack.o: stack.h main.h
maze.o: maze.h main.h
clean:
-rm main *.o
.PHONY: clean
按照惯例,用all做缺省目标。现在还有一点比较麻烦,在写main.o、stack.o和maze.o这三个目标的规则时要查看源代码,找出它们依赖于哪些头文件,这很容易出错,一是因为有的头文件包含在另一个头文件中,在写规则时很容易遗漏,二是如果以后修改源代码改变了依赖关系,很可能忘记修改Makefile的规则。为了解决这个问题,可以用gcc的-M选项自动生成目标文件和源文件的依赖关系:
$ gcc -M main.c
main.o: main.c /usr/include/stdio.h /usr/include/features.h \
/usr/include/sys/cdefs.h /usr/include/bits/wordsize.h \
/usr/include/gnu/stubs.h /usr/include/gnu/stubs-32.h \
/usr/lib/gcc/i486-linux-gnu/4.3.2/include/stddef.h \
/usr/include/bits/types.h /usr/include/bits/typesizes.h \
/usr/include/libio.h /usr/include/_G_config.h /usr/include/wchar.h \
/usr/lib/gcc/i486-linux-gnu/4.3.2/include/stdarg.h \
/usr/include/bits/stdio_lim.h /usr/include/bits/sys_errlist.h main.h \
stack.h maze.h
-M选项把stdio.h以及它所包含的系统头文件也找出来了,如果我们不需要输出系统头文件的依赖关系,可以用-MM选项:
$ gcc -MM *.c
main.o: main.c main.h stack.h maze.h
maze.o: maze.c maze.h main.h
stack.o: stack.c stack.h main.h
接下来的问题是怎么把这些规则包含到Makefile中,GNU make的官方手册建议这样写:
all: main
main: main.o stack.o maze.o
gcc $^ -o $@
clean:
-rm main *.o
.PHONY: clean
sources = main.c stack.c maze.c
include $(sources:.c=.d)
%.d: %.c
set -e; rm -f $@; \
$(CC) -MM $(CPPFLAGS) $< > $@.$$$$; \
sed 's,\($*\)\.o[ :]*,\1.o $@ : ,g' < $@.$$$$ > $@; \
rm -f $@.$$$$
sources变量包含我们要编译的所有.c文件,$(sources:.c=.d)是一个变量替换语法,把sources变量中每一项的.c替换成.d,所以include这一句相当于:
include main.d stack.d maze.d
类似于C语言的#include指示,这里的include表示包含三个文件main.d、stack.d和maze.d,这三个文件也应该符合Makefile的语法。如果现在你的工作目录是干净的,只有.c文件、.h文件和Makefile,运行make的结果是:
$ make
Makefile:13: main.d: No such file or directory
Makefile:13: stack.d: No such file or directory
Makefile:13: maze.d: No such file or directory
set -e; rm -f maze.d; \
cc -MM maze.c > maze.d.$$; \
sed 's,\(maze\)\.o[ :]*,\1.o maze.d : ,g' < maze.d.$$ > maze.d; \
rm -f maze.d.$$
set -e; rm -f stack.d; \
cc -MM stack.c > stack.d.$$; \
sed 's,\(stack\)\.o[ :]*,\1.o stack.d : ,g' < stack.d.$$ > stack.d; \
rm -f stack.d.$$
set -e; rm -f main.d; \
cc -MM main.c > main.d.$$; \
sed 's,\(main\)\.o[ :]*,\1.o main.d : ,g' < main.d.$$ > main.d; \
rm -f main.d.$$
cc -c -o main.o main.c
cc -c -o stack.o stack.c
cc -c -o maze.o maze.c
gcc main.o stack.o maze.o -o main
一开始找不到.d文件,所以make会报警告。但是make会把include的文件名也当作目标来尝试更新,而这些目标适用模式规则%.d: %c,所以执行它的命令列表,比如生成maze.d的命令:
set -e; rm -f maze.d; \
cc -MM maze.c > maze.d.$$; \
sed 's,\(maze\)\.o[ :]*,\1.o maze.d : ,g' < maze.d.$$ > maze.d; \
rm -f maze.d.$$
注意,虽然在Makefile中这个命令写了四行,但其实是一条命令,make只创建一个Shell进程执行这条命令,这条命令分为5个子命令,用;号隔开,并且为了美观,用续行符\拆成四行来写。执行步骤为:
set -e命令设置当前Shell进程为这样的状态:如果它执行的任何一条命令的退出状态非零则立刻终止,不再执行后续命令。
把原来的maze.d删掉。
重新生成maze.c的依赖关系,保存成文件maze.d.1234(假设当前Shell进程的id是1234)。注意,在Makefile中$有特殊含义,如果要表示它的字面意思则需要写两个$,所以Makefile中的四个$传给Shell变成两个$,两个$在Shell中表示当前进程的id,一般用它给临时文件起名,以保证文件名唯一。
这个sed命令比较复杂,就不细讲了,主要作用是查找替换。maze.d.1234的内容应该是maze.o: maze.c maze.h main.h,经过sed处理之后存为maze.d,其内容是maze.o maze.d: maze.c maze.h main.h。
最后把临时文件maze.d.1234删掉。
不管是Makefile本身还是被它包含的文件,只要有一个文件在make过程中被更新了,make就会重新读取整个Makefile以及被它包含的所有文件,现在main.d、stack.d和maze.d都生成了,就可以正常包含进来了(假如这时还没有生成,make就要报错而不是报警告了),相当于在Makefile中添了三条规则:
main.o main.d: main.c main.h stack.h maze.h
maze.o maze.d: maze.c maze.h main.h
stack.o stack.d: stack.c stack.h main.h
如果我在main.c中加了一行#include "foo.h",那么:
main.c的修改日期变了,根据第一条规则要重新生成main.o和main.d。
现在main.d的内容更新为main.o main.d: main.c main.h stack.h maze.h foo.h。
由于main.d被Makefile包含,main.d被更新又导致make重新读取整个Makefile,把新的main.d包含进来,于是新的依赖关系生效了。
CC=g++
CFLAGS=-g
INCLUDE_DIR=./
OUTDIR=./Test/
SRC=$(wildcard *.cpp)
SRC+=$(wildcard mo/*.cpp)
all: main
OBJS=$(patsubst %.o,$(OUTDIR)%.o,$(SRC:.cpp=.o))
main:$(OBJS)
g++ $^ -o $(OUTDIR)$@
$(OBJS):$(OUTDIR)%.o:%.cpp
$(CC) -c $(CPPFLAGS) $< -o $@;
clean:
-rm -rf $(OUTDIR)*
.PHONY: clean
DSYMBOLS=$(patsubst %.cpp,$(OUTDIR)%.d,$(SRC))
-include $(DSYMBOLS)
$(DSYMBOLS):$(OUTDIR)%.d:%.cpp
mkdir -p $(dir $@);\
set -e; rm -f $@; \
$(CC) -MM $(CPPFLAGS) $(INCLUDE_DIR) $< > $@.$$$$; \
sed 's,\($(notdir $*)\)\.o[ :]*,$*.o $@ : ,g' < $@.$$$$ > $@; \
rm -f $@.$$$$
目录结构如下:
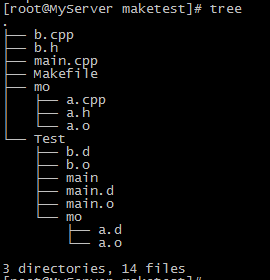
增加了:扫描当前目录下所有文件的功能(深度三层)
CC=g++
CFLAGS=-g
OUTDIR=./
INCLUDE_DIR=./
EXCLUDE_DIRS=./Test% mo
TEMPDIR=test
DIRS := $(shell find . -maxdepth 3 -type d)
DIRS := $(filter-out $(EXCLUDE_DIRS),$(DIRS))
SRC=$(patsubst ./%,%,$(foreach dir,$(DIRS),$(wildcard $(dir)/*.cpp)))
#SRC=$(wildcard *.cpp)
#SRC+=$(wildcard mo/*.cpp)
#SRC=$(shell $(SRC) | sed 's/^\.\///g' )
$(warning $(SRC))
all: main
OBJS=$(patsubst %.cpp,$(TEMPDIR)/%.o,$(SRC))
$(warning $(OBJS))
main:$(OBJS)
g++ $^ -o $@;\
$(shell mv $(TEMPDIR)/main ./)
$(OBJS):$(TEMPDIR)/%.o:%.cpp
$(CC) -c $(CPPFLAGS) $< -o $@;
clean:
-rm -rf $(TEMPDIR)*
.PHONY: clean
DSYMBOLS=$(patsubst %.cpp,$(TEMPDIR)/%.d,$(SRC))
-include $(DSYMBOLS)
$(warning $(DSYMBOLS))
$(DSYMBOLS):$(TEMPDIR)/%.d:%.cpp
mkdir -p $(dir $@) ;\
set -e; rm -f $@; \
$(CC) -MM $(CPPFLAGS) $(INCLUDE_DIR) $< > $@.$$$$; \
sed 's,\($(notdir $*)\)\.o[ :]*,$*.o $@ : ,g' < $@.$$$$ > $@; \
rm -f $@.$$$$
说明:
1、静态模式
静态模式可以更加容易地定义多目标的规则,可以让我们的规则变得更加的有弹性和灵活。我们还是先来看一下语法:
<targets ...>: <target-pattern>: <prereq-patterns ...>
<commands>
...
targets定义了一系列的目标文件,可以有通配符。是目标的一个集合。
target-parrtern是指明了targets的模式,也就是的目标集模式。
prereq-parrterns是目标的依赖模式,它对target-parrtern形成的模式再进行一次依赖目标的定义。
这样描述这三个东西,可能还是没有说清楚,还是举个例子来说明一下吧。如果我们的<target-parrtern>定义成“%.o”,意思是我们的<target>集合中都是以“.o”结尾的,而如果我们的<prereq-parrterns>定义成“%.c”,意思是对<target-parrtern>所形成的目标集进行二次定义,其计算方法是,取<target-parrtern>模式中的“%”(也就是去掉了[.o]这个结尾),并为其加上[.c]这个结尾,形成的新集合。
所以,我们的“目标模式”或是“依赖模式”中都应该有“%”这个字符,如果你的文件名中有“%”那么你可以使用反斜杠“/”进行转义,来标明真实的“%”字符。
看一个例子:
objects = foo.o bar.o
all: $(objects)
$(objects): %.o: %.c
$(CC) -c $(CFLAGS) $< -o $@
上面的例子中,指明了我们的目标从$object中获取,“%.o”表明要所有以“.o”结尾的目标,也就是“foo.o bar.o”,也就是变量$object集合的模式,而依赖模式“%.c”则取模式“%.o”的“%”,也就是“foo bar”,并为其加下“.c”的后缀,于是,我们的依赖目标就是“foo.c bar.c”。而命令中的“$<”和“$@”则是自动化变量,“$<”表示所有的依赖目标集(也就是“foo.c bar.c”),“$@”表示目标集(也就是“foo.o bar.o”)。于是,上面的规则展开后等价于下面的规则:
foo.o : foo.c
$(CC) -c $(CFLAGS) foo.c -o foo.o
bar.o : bar.c
$(CC) -c $(CFLAGS) bar.c -o bar.o
试想,如果我们的“%.o”有几百个,那种我们只要用这种很简单的“静态模式规则”就可以写完一堆规则,实在是太有效率了。“静态模式规则”的用法很灵活,如果用得好,那会一个很强大的功能。再看一个例子:
files = foo.elc bar.o lose.o
$(filter %.o,$(files)): %.o: %.c
$(CC) -c $(CFLAGS) $< -o $@
$(filter %.elc,$(files)): %.elc: %.el
emacs -f batch-byte-compile $<
$(filter %.o,$(files))表示调用Makefile的filter函数,过滤“$filter”集,只要其中模式为“%.o”的内容。其的它内容,我就不用多说了吧。这个例字展示了Makefile中更大的弹性。
2、自动生成依赖性
在Makefile中,我们的依赖关系可能会需要包含一系列的头文件,比如,如果我们的main.c中有一句“#include "defs.h"”,那么我们的依赖关系应该是:
main.o : main.c defs.h
但是,如果是一个比较大型的工程,你必需清楚哪些C文件包含了哪些头文件,并且,你在加入或删除头文件时,也需要小心地修改Makefile,这是一个很没有维护性的工作。为了避免这种繁重而又容易出错的事情,我们可以使用C/C++编译的一个功能。大多数的C/C++编译器都支持一个“-M”的选项,即自动找寻源文件中包含的头文件,并生成一个依赖关系。例如,如果我们执行下面的命令:
cc -M main.c
其输出是:
main.o : main.c defs.h
于是由编译器自动生成的依赖关系,这样一来,你就不必再手动书写若干文件的依赖关系,而由编译器自动生成了。需要提醒一句的是,如果你使用GNU的C/C++编译器,你得用“-MM”参数,不然,“-M”参数会把一些标准库的头文件也包含进来。
gcc -M main.c的输出是:
main.o: main.c defs.h /usr/include/stdio.h /usr/include/features.h /
/usr/include/sys/cdefs.h /usr/include/gnu/stubs.h /
/usr/lib/gcc-lib/i486-suse-linux/2.95.3/include/stddef.h /
/usr/include/bits/types.h /usr/include/bits/pthreadtypes.h /
/usr/include/bits/sched.h /usr/include/libio.h /
/usr/include/_G_config.h /usr/include/wchar.h /
/usr/include/bits/wchar.h /usr/include/gconv.h /
/usr/lib/gcc-lib/i486-suse-linux/2.95.3/include/stdarg.h /
/usr/include/bits/stdio_lim.h
gcc -MM main.c的输出则是:
main.o: main.c defs.h
那么,编译器的这个功能如何与我们的Makefile联系在一起呢。因为这样一来,我们的Makefile也要根据这些源文件重新生成,让Makefile自已依赖于源文件?这个功能并不现实,不过我们可以有其它手段来迂回地实现这一功能。GNU组织建议把编译器为每一个源文件的自动生成的依赖关系放到一个文件中,为每一个“name.c”的文件都生成一个“name.d”的Makefile文件,[.d]文件中就存放对应[.c]文件的依赖关系。
于是,我们可以写出[.c]文件和[.d]文件的依赖关系,并让make自动更新或自成[.d]文件,并把其包含在我们的主Makefile中,这样,我们就可以自动化地生成每个文件的依赖关系了。
这里,我们给出了一个模式规则来产生[.d]文件:
%.d: %.c
@set -e; rm -f $@; \
$(CC) -M $(CPPFLAGS) $< > $@.$$$$; \
sed 's,\($*\)\.o[ :]*,\1.o $@ : ,g' < $@.$$$$ > $@; \
rm -f $@.$$$$
这个规则的意思是,所有的[.d]文件依赖于[.c]文件,“rm -f $@”的意思是删除所有的目标,也就是[.d]文件,第二行的意思是,为每个依赖文件“$<”,也就是[.c]文件生成依赖文件,“$@”表示模式“%.d”文件,如果有一个C文件是name.c,那么“%”就是“name”,“$$$$”在Makefile中$有特殊含义,如果要表示它的字面意思则需要写两个$,所以Makefile中的四个$传给Shell变成两个$,两个$在Shell中表示当前进程的id,一般用它给临时文件起名,以保证文件名唯一,第二行生成的文件有可能是“name.d.12345”,第三行使用sed命令做了一个替换,关于sed命令的用法请参看相关的使用文档。第四行就是删除临时文件。
总而言之,这个模式要做的事就是在编译器生成的依赖关系中加入[.d]文件的依赖,即把依赖关系:
main.o : main.c defs.h
转成:
main.o main.d : main.c defs.h
于是,我们的[.d]文件也会自动更新了,并会自动生成了,当然,你还可以在这个[.d]文件中加入的不只是依赖关系,包括生成的命令也可一并加入,让每个[.d]文件都包含一个完赖的规则。一旦我们完成这个工作,接下来,我们就要把这些自动生成的规则放进我们的主Makefile中。我们可以使用Makefile的“include”命令,来引入别的Makefile文件(前面讲过),例如:
sources = foo.c bar.c
include $(sources:.c=.d)
上述语句中的“$(sources:.c=.d)”中的“.c=.d”的意思是做一个替换,把变量$(sources)所有[.c]的字串都替换成[.d],关于这个“替换”的内容,在后面我会有更为详细的讲述。当然,你得注意次序,因为include是按次来载入文件,最先载入的[.d]文件中的目标会成为默认目标。
在$(CC) -MM $(CPPFLAGS) $(INCLUDE_DIR) $< > $@.$$$$;中 $(INCLUDE_DIR) 是必不可少的,否则会出来找不到文件的错误
3、书写命令
每条规则中的命令和操作系统Shell的命令行是一致的。make会一按顺序一条一条的执行命令,每条命令的开头必须以[Tab]键开头,除非,命令是紧跟在依赖规则后面的分号后的。在命令行之间中的空格或是空行会被忽略,但是如果该空格或空行是以Tab键开头的,那么make会认为其是一个空命令。
我们在UNIX下可能会使用不同的Shell,但是make的命令默认是被“/bin/sh”——UNIX的标准Shell解释执行的。除非你特别指定一个其它的Shell。Makefile中,“#”是注释符,很像C/C++中的“//”,其后的本行字符都被注释。
4、显示命令
通常,make会把其要执行的命令行在命令执行前输出到屏幕上。当我们用“@”字符在命令行前,那么,这个命令将不被make显示出来,最具代表性的例子是,我们用这个功能来像屏幕显示一些信息。如:
@echo 正在编译XXX模块......
当make执行时,会输出“正在编译XXX模块......”字串,但不会输出命令,如果没有“@”,那么,make将输出:
echo 正在编译XXX模块......
正在编译XXX模块......
如果make执行时,带入make参数“-n”或“--just-print”,那么其只是显示命令,但不会执行命令,这个功能很有利于我们调试我们的Makefile,看看我们书写的命令是执行起来是什么样子的或是什么顺序的。
而make参数“-s”或“--slient”则是全面禁止命令的显示。
5、命令执行
当依赖目标新于目标时,也就是当规则的目标需要被更新时,make会一条一条的执行其后的命令。需要注意的是,如果你要让上一条命令的结果应用在下一条命令时,你应该使用分号分隔这两条命令。比如你的第一条命令是cd命令,你希望第二条命令得在cd之后的基础上运行,那么你就不能把这两条命令写在两行上,而应该把这两条命令写在一行上,用分号分隔。如:
示例一:
exec:
cd /home/hchen
pwd
示例二:
exec:
cd /home/hchen; pwd
当我们执行“make exec”时,第一个例子中的cd没有作用,pwd会打印出当前的Makefile目录,而第二个例子中,cd就起作用了,pwd会打印出“/home/hchen”。
make一般是使用环境变量SHELL中所定义的系统Shell来执行命令,默认情况下使用UNIX的标准Shell——/bin/sh来执行命令。但在MS-DOS下有点特殊,因为MS-DOS下没有SHELL环境变量,当然你也可以指定。如果你指定了UNIX风格的目录形式,首先,make会在SHELL所指定的路径中找寻命令解释器,如果找不到,其会在当前盘符中的当前目录中寻找,如果再找不到,其会在PATH环境变量中所定义的所有路径中寻找。MS-DOS中,如果你定义的命令解释器没有找到,其会给你的命令解释器加上诸如“.exe”、“.com”、“.bat”、“.sh”等后缀。
6、命令出错
每当命令运行完后,make会检测每个命令的返回码,如果命令返回成功,那么make会执行下一条命令,当规则中所有的命令成功返回后,这个规则就算是成功完成了。如果一个规则中的某个命令出错了(命令退出码非零),那么make就会终止执行当前规则,这将有可能终止所有规则的执行。
有些时候,命令的出错并不表示就是错误的。例如mkdir命令,我们一定需要建立一个目录,如果目录不存在,那么mkdir就成功执行,万事大吉,如果目录存在,那么就出错了。我们之所以使用mkdir的意思就是一定要有这样的一个目录,于是我们就不希望mkdir出错而终止规则的运行。
为了做到这一点,忽略命令的出错,我们可以在Makefile的命令行前加一个减号“-”(在Tab键之后),标记为不管命令出不出错都认为是成功的。如:
clean:
-rm -f *.o
还有一个全局的办法是,给make加上“-i”或是“--ignore-errors”参数,那么,Makefile中所有命令都会忽略错误。而如果一个规则是以“.IGNORE”作为目标的,那么这个规则中的所有命令将会忽略错误。这些是不同级别的防止命令出错的方法,你可以根据你的不同喜欢设置。
还有一个要提一下的make的参数的是“-k”或是“--keep-going”,这个参数的意思是,如果某规则中的命令出错了,那么就终目该规则的执行,但继续执行其它规则。
附注:
1.Makefile 文件名 不可写为MakeFile,注意大小写
2.如出现错误missing separator. Stop. 一般为makefile命令不是以TAB开始导致的,很多情况为四个空格导致的错误,Makefile命令必须以TAB开始
3.Makefile的静态模式:
<targets ...>: <target-pattern>: <prereq-patterns ...>
<commands>
其中的targets就是其它命令如 %.d:%.cpp中前面的%d的部分.target-pattern就是替换字符串的find字符串,这个不是目标,第一个targets才是目标,第三个参数prereq-patterns在替换完成后就是%.d:%.cpp中的%.cpp的部分
4.$(wildcard *.cpp) 为展开所取到的文件名,即*.cpp换为a.cpp b.cpp ....
5.$(patsubst %.o,$(OUTDIR)%.o,$(SRC:.cpp=.o)) $(SRC:.cpp=.o)为把$(SRC)变量中的.cpp替换成.o, $(patsubst %.o,$(OUTDIR)%.o,$(SRC:.cpp=.o)) 为把替换成.o的$(SRC)变量中,把符合%.o的的字符串替换成$(OUTDIR)%.o,意思就是在所有的以.o结尾的文件名前,加上一个字符串
6.$$$$ $在Makefile中为特殊字符.四个$符号传给SEHLL后就变成 $$ 符号.$$ 在SHELL中意思为进程号
7.以下代码中,Makefile为目标链的模式,make依赖于$(OBJS),$(OBJS)依赖于$(OUTDIR)%.o:%.cpp中的.cpp,如果.cpp文件是不存在的就会报错,如果.cpp文件是存在的,就执行makefile
main:$(OBJS)
g++ $^ -o $(OUTDIR)$@
$(OBJS):$(OUTDIR)%.o:%.cpp
$(CC) -c $(CPPFLAGS) $< -o $@;
8.Makefile中的变量都是变局模式,即后面的替换前面的,例如:A=a.o b.o ; $(patsubst $(A),%.o,aa%.o); A=c.o d.o; 如果代码这样写,最前的A=a.o b.o就会被后面的A=c.o d.o覆盖,而且 $(patsubst $(A),%.o,aa%.o) 里面用的到 $(A) 也是 c.o d.o 这个与C++的写法很不一样,这个要格外注意
9.$(DSYMBOLS):$(OUTDIR)%.d:%.cpp 例如: $(DSYMBOLS)为 Test/mo/a.d Test/b.d Test/main.d , 那么$(OUTDIR)%.d里面的%取的就是 mo/a b main , %.cpp里面的%也是 mo/a b main ,就是第一个冒号后面的表达式匹配目标的任一个字符串,里面的%号,就是匹配到的字符串,第二个冒号后面的%就是前面的%取到的值
10. $* 是指模式里面%取到的字符串, $@ 指目标, $< 指依赖, $*一般比$@取到的要少
11.sed 's,\($(notdir $*)\)\.o[ :]*,$*.o $@ : ,g' < $@.$$$$ > $@; 这个替换的意思为把 Test/mo/a.o Test/main.o : 替换为Test/mo/a.o Test/mo/a.d Test/main.o Test/main.d: ,其中 $@ 前面的 < 符号是可以省略的
12.取得一个目录下的文件夹: ls -l | grep ^d | awk '{print $9}' | xargs
13.循环处理
for dirname in `ls -l | grep ^d | awk '{print $9}' | xargs`;do
echo $dirname
done
14. sed 's,\(stack\)\.o[ :]*,\1.o stack.d : ,g' < stack.d.$$ > stack.d; \ 中的大于号和小于号的意思是:sed从stack.d.$$文件读取内容进行替换,然后输出到stack.d文件中
15.-include FILENAMES...
使用这种方式时,当所要包含的文件不存在时不会有错误提示、make也不会退出;
16.在makefile中打印警告或者错误消息的方法:$(warning xxxxx)或者$(error xxxxx) ,输出变量方式为:$(warning $(XXX))
17. wildcard : 扩展通配符; notdir : 去除路径; patsubst :替换通配符 这三个是makefile的扩展函数
例子:
建立一个测试目录,在测试目录下建立一个名为sub的子目录
$ mkdir test
$ cd test
$ mkdir sub
在test下,建立a.c和b.c2个文件,在sub目录下,建立sa.c和sb.c2 个文件
建立一个简单的Makefile
src=$(wildcard *.c ./sub/*.c)
dir=$(notdir $(src))
obj=$(patsubst %.c,%.o,$(dir) )
all:
@echo $(src)
@echo $(dir)
@echo $(obj)
@echo "end"
执行结果分析:
第一行输出:
a.c b.c ./sub/sa.c ./sub/sb.c
wildcard把 指定目录 ./ 和 ./sub/ 下的所有后缀是c的文件全部展开。
第二行输出:
a.c b.c sa.c sb.c
notdir把展开的文件去除掉路径信息
第三行输出:
a.o b.o sa.o sb.o
在$(patsubst %.c,%.o,$(dir) )中,patsubst把$(dir)中的变量符合后缀是.c的全部替换成.o,
任何输出。
或者可以使用
obj=$(dir:%.c=%.o)
效果也是一样的。
这里用到makefile里的替换引用规则,即用您指定的变量替换另一个变量。
它的标准格式是
$(var:a=b) 或 ${var:a=b}
它的含义是把变量var中的每一个值结尾用b替换掉a
今天在研究makefile时在网上看到一篇文章,介绍了使用函数wildcard得到指定目录下所有的C语言源程序文件名的方法,这下好了,不用手工一个一个指定需要编译的.c文件了,方法如下:
SRC = $(wildcard *.c)
等于指定编译当前目录下所有.c文件,如果还有子目录,比如子目录为inc,则再增加一个wildcard函数,象这样:
SRC = $(wildcard *.c) $(wildcard inc/*.c)
也可以指定汇编源程序:
ASRC = $(wildcard *.S)
这样一来,makefile模板可修改的基本就是AVR名称和时钟频率了,其它的一般不用动了。
PS:针对patsubst我们来好好聊一聊
这是个模式替换函数
格式:$(patsubst <pattern>,<replacement>,<text> )
名称:模式字符串替换函数——patsubst。
功能:查找<text>中的单词(单词以“空格”、“Tab”或“回车”“换行”分隔)是否符合模式<pattern>,如果匹配的话,则以<replacement>替换。这里,<pattern>可以包括通配符“%”,表示任意长度的字串。如果<replacement>中也包含“%”,那么,<replacement>中的这个“%”将是<pattern>中的那个“%”所代表的字串。(可以用“\”来转义,以“\%”来表示真实含义的“%”字符)
返回:函数返回被替换过后的字符串。
示例:
$(patsubst %.c,%.o,x.c.c bar.c)
把字串“x.c.c bar.c”符合模式[%.c]的单词替换成[%.o],返回结果是“x.c.o bar.o”
make中有个变量替换引用
对于一个已经定义的变量,可以使用“替换引用”将其值中的后缀字符(串)使用指定的字符(字符串)替换。格式为“$(VAR:A=B)”(或者“${VAR:A=B}”),意思是,替换变量“VAR”中所有“A”字符结尾的字为“B”结尾的字。“结尾”的含义是空格之前(变量值多个字之间使用空格分开)。而对于变量其它部分的“A”字符不进行替换。例如:
foo := a.o b.o c.o
bar := $(foo:.o=.c)
在这个定义中,变量“bar”的值就为“a.c b.c c.c”。使用变量的替换引用将变量“foo”以空格分开的值中的所有的字的尾字符“o”替换为“c”,其他部分不变。如果在变量“foo”中如果存在“o.o”时,那么变量“bar”的值为“a.c b.c c.c o.c”而不是“a.c b.c c.c c.c”。
它是patsubst的一个简化,那么到底是简化成了什么样子呢
CROSS=
CC=$(CROSS)gcc
CFLAGS= -Wall
LDFLAGS=
PKG = src
SRCS = $(wildcard $(PKG)/inc/*.c) $(wildcard $(PKG)/*.c)
BOJS = $(patsubst %.c,%.o,$(SRCS))
#BOJS = $(SRCS: .c = .o)
#%.o:%.c
# $(CC) -c $< $(CFLAGS) -o $@
.PHONY:main
main:$(BOJS)
-$(CC) -o $@ $(CFLAGS) $^ $(LDFLAGS)
-mv main ./myfile
起初使用的是变量替换引用的方式,但是却始终不生成中间的.o文件,但是使用patsubst后,一切正常了
18.Makefile 是先加载后执行的方式来运行的,因引可以在加载完其它Makefile之后再改变包含的那个MakeFile里面的变量来执行特殊化的逻辑
19.Makefile 里面行前的 @ 符号为隐藏当前输出的意思
20. 执行另外的Makefile文件 使用 make -j8 -f CenterServer.mak -f为执行文件的意思
21. 可以新增目标 test 来执行一些 MakeFile 变量的查看等逻辑
22. 为了提升编译的速度,我们可以通过“make -jn”并行的执行make动作。但是,在某些情况下(多目录多Makefile,且Makefile有比较复杂的依赖关系时),并行make会导致失败。这时就需要强制串行的执行make,具体方法有下面几种:
(1). 在Makefile中加入“.NOTPARALLEL:”(伪目标),指定某些目标需要串行的编译。
如果没有指定目标,则Makefile中所有的目标都会串行的处理:
.NOTPARALLEL:
还可以指定具体要串行编译的目标:
.NOTPARALLEL: target1 target2
(2). 在Makfile中加入 “MAKEFLAGS = -j1”,强制覆盖掉“make -jn”选项。
23.一些函数
objects=main1.o foo.o main2.o bar.o
mains=main1.o main2.o
$(filter-out $(mains),$(objects)) 返回值是“foo.o bar.o”。
$(sort <list>) sort函数会去掉<list>中相同的单词
发布时间: 9年前【代码相关】247人已围观【返回】【回到顶端】
很赞哦! (1)
上一篇:栈大小和内存分部问题
相关文章




点击排行
 单一职责原则、里氏替换原则、依赖倒置原则
单一职责原则、里氏替换原则、依赖倒置原则
站长推荐
 接口隔离原则、迪米特法则、开闭原则
接口隔离原则、迪米特法则、开闭原则







猜你喜欢
站点信息
- 建站时间:2016-04-01
- 文章统计:728条
- 文章评论:82条
- QQ群二维码:扫描二维码,互相交流
