



01Lua循环与迭代器函数
Lua 语言提供了以下几种循环处理方式:
while 循环:在条件为 true 时,让程序重复地执行某些语句。执行语句前会先检查条件是否为 true
for 循环:重复执行指定语句,重复次数可在 for 语句中控制。
repeat...until :重复执行循环,直到 指定的条件为真时为止
循环嵌套:可以在循环内嵌套一个或多个循环语句(while do ... end;for ... do ... end;repeat ... until;)

02Lua的rawset和rawget浅析
raw:原始的,未加工的。
rawset/rawget:对“原始的”表进行直接的赋值/取值操作。
所以,raw方法就是忽略table对应的metatable,绕过metatable的行为约束,强制对原始表进行一次原始的操作,也就是一次不考虑元表的简单更新。另外,一次原始的操作其实并不会加速代码执行的速度,效率一样。

03gcc -D选项 编译时添加宏定义
使用 gcc -D选项 可以在编译时添加宏定义选择性的编译代码
例:gcc debugtest.c -o debugtest.exe -D DEBUG
即在编译时加入 DEBUG 宏


04gcc的编译参数-fPIC
non-PIC 与 PIC 在代码的区别主要在于 access global data, jump label 的不同。
比如一条 access global data 的指令,
non-PIC 的形式是:ld r3,var1
PIC 的形式则是:ld r3,var1-offset@GOT
意思是从 GOT 表的 index 为 var1-offset的地方处指示的地址处装载一个值,即var1-offset@GOT处的4个 byte 其实就是 var1的地址。这个地址只有在运行的时候才知道,是由 dynamic-loader(ld-linux.so)填进去的。
再比如 jump label 指令
non-PIC 的形式是:jump printf ,意思是调用 printf。
PIC 的形式则是:jump printf-offset@GOT,
意思是跳到 GOT 表的 index 为 printf-offset 的地方处指示的地址去执行,
这个地址处的代码摆放在 .plt section,
每个外部函数对应一段这样的代码,其功能是呼叫dynamic-loader(ld-linux.so)来查找函数的地址(本例中是
printf),然后将其地址写到 GOT 表的 index 为 printf-offset的地方,同时执行这个函数。这样,第2次呼叫 printf 的时候,就会直接跳到 printf 的地址,而不必再查找了。

05AT&T与Intel汇编语言的比较
在Intel的语法中,寄存器和和立即数都没有前缀。但是在AT&T中,寄存器前冠以“%”,而立即数前冠以“$”。在Intel的语法中,十六进制和二进制立即数后缀分别冠以“h”和“b”,而在AT&T中,十六进制立即数前冠以“0x”。
1、直接跳转:跳转目标是作为指令封一部分编码。 如:jmp 0x2358, 直接跳转是跳转到这个地址执行指令,是根据下一条指令位置作的加减法。
objdump -d xxxx 里面看到的汇编指令(如下图),虽然显示是目标指令的地址,但看机器码会发现,这个值实际上是一个偏移值。
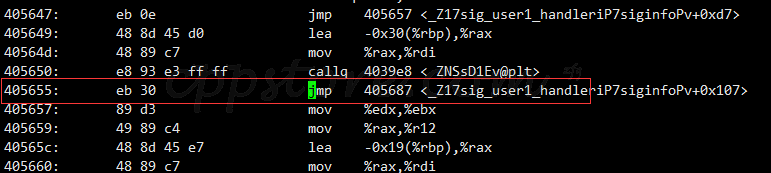
405678-405657=30 (1、这个是16进制的计算,不是10进制的。2、需要用405657即下一条指令的地址作为基准作偏移,实际上是加上了本身这条指令占用的字节数)
jmp的机器码有三个:e9、eb、ff (ff 是用于绝对跳转的,就是跳转到这个地址执行;e9和eb是相对跳转的,就是拿下一条指令的地址加上后面的偏移量)
2、间接跳转:目标是从寄存器或存储器位置读出来的。如:jmp *%eax间接跳转字节码基本都是ff,也是绝对跳转。就是跳转到这个地址。这个区别于e9和eb是相对地址。
3、e9和ff 是扩展到64位的

06函数调用-汇编分析
汇编函数调用过程
1、压栈: 函数参数压栈,返回地址压栈
2、跳转: 跳转到函数所在代码处执行
3、执行: 执行函数代码
4、返回: 平衡堆栈,找出之前的返回地址,跳转回之前的调用点之后,完成函数调用
call:把call指令的下一条指令地址作为本次函数调用的返回地址压栈,然后使用jmp指令修改指令指针寄存器EIP,使cpu执行被调用函数的指令代码。
ret:它表示取出当前栈顶值,作为返回地址,并将指令指针寄存器EIP修改为该值,实现函数返回。
ESP:栈指针寄存器(extended stack pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的栈顶。
EBP:基址指针寄存器(extended base pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的底部。


07float和double表示范围和精度
范围:float的指数范围为-127--128,double的范围是-1023-1024。
负指数决定了绝对值最小的非零数,正指数决定了绝对值最大的数。也即决定了范围。
也即float的范围为-2^128-2^128,double的范围是-2^1024-2^1024。
精度:float和double的精度是由尾数位决定的。浮点数在内存中是按照科学计数法来存储的,其整数部分始终是一个隐藏着的1。由于他是不变的,因此对精度不会造成影响的。
float精度范围是:2^23一共7位,因此最多能表示7位,但是能保证的是6位。
double的精度范围是2^52一共16位,同理最多能表示16位,但是能保证的是15位。

08内存对齐算法
由此可见,我们只要对数据补齐对齐所需最少数据,然后将补齐位置0就可以实现对齐计算。
(1)(align-1),表示对齐所需的对齐位,如:2字节对齐为1,4字节为11,8字节为111,16字节为1111...
(2)(x+(align-1)),表示x补齐对齐所需数据
(3)&~(align-1),表示去除由于补齐造成的多余数据
(4) (x+(align-1))&~(align-1),表示对齐后的数据
举个例子:如8字节对齐。起始地始是6
6 + (8 - 1)=0000 0110 + 0000 0111 = 0000 1101
0000 1101 & ~(0000 0111) = 0000 1000 //去除由于补齐造成的多余数据

09一个低级Illegal instruction错误的定位--忽略编译期警告就得加倍偿还
INFO_LOG("id[%s] ...", packet->strid, ...);
当packet->strid为string类型,不是char*类型时
会报编译警告
ProcessHeartbeat.cpp:408: warning: cannot pass objects of non-POD type âstruct std::stringâ through â...â; call will abort at runtime
但不会报error,但会在运行时崩溃,Program terminated with signal 4,Illegal instruction.


10如何加快C++代码的编译速度
C++代码一直以其运行时的高性能高调面对世人, 但是说起编译速度,却只有低调的份了。比如我现在工作的源代码,哪怕使用Incredibuild调动近百台机子,一个完整的build也需要四个小时,恐怖!!!虽然平时开发一般不需要在本地做完整的build,但编译几个相关的工程就够你等上好一段时间的了(老外管这个叫monkey around,相当形象)。想想若干年在一台单核2.8GHZ上工作时的场景 - 面前放本书,一点build按钮,就低头读一会书~~~往事不堪回首。
11C++中复制构造函数可以调取其他对象中的私有变量
封装是编译期的概念,是针对类型而非对象的,在类的成员函数中可以访问同类型实例对象的私有成员变量.
12为什么多线程读写 shared_ptr 要加锁?
(shared_ptr)的引用计数本身是安全且无锁的,但对象的读写则不是,因为 shared_ptr 有两个数据成员,读写操作不能原子化。根据文档(http://www.boost.org/doc/libs/release/libs/smart_ptr/shared_ptr.htm#ThreadSafety), shared_ptr 的线程安全级别和内建类型、标准库容器、std::string 一样,即:
• 一个 shared_ptr 对象实体可被多个线程同时读取(文档例1);
• 两个 shared_ptr 对象实体可以被两个线程同时写入(例2),“析构”算写操作;
• 如果要从多个线程读写同一个 shared_ptr 对象,那么需要加锁(例3~5)。
请注意,以上是 shared_ptr 对象本身的线程安全级别,不是它管理的对象的线程安全级别。
后文(p.18)则介绍如何高效地加锁解锁。本文则具体分析一下为什么“因为 shared_ptr 有两个数据成员,读写操作不能原子化”使得多线程读写同一个 shared_ptr 对象需要加锁。这个在我看来显而易见的结论似乎也有人抱有疑问,那将导致灾难性的后果,值得我写这篇文章。本文以 boost::shared_ptr 为例,与 std::shared_ptr 可能略有区别。
shared_ptr 的数据结构
shared_ptr 是引用计数型(reference counting)智能指针,几乎所有的实现都采用在堆(heap)上放个计数值(count)的办法(除此之外理论上还有用循环链表的办法,不过没有实例)。具体来说,shared_ptr<Foo> 包含两个成员,一个是指向 Foo 的指针 ptr,另一个是 ref_count 指针(其类型不一定是原始指针,有可能是 class 类型,但不影响这里的讨论),指向堆上的 ref_count 对象。ref_count 对象有多个成员,具体的数据结构如图 1 所示,其中 deleter 和 allocator 是可选的。



点击排行
 单一职责原则、里氏替换原则、依赖倒置原则
单一职责原则、里氏替换原则、依赖倒置原则
站长推荐
 接口隔离原则、迪米特法则、开闭原则
接口隔离原则、迪米特法则、开闭原则







猜你喜欢
站点信息
- 建站时间:2016-04-01
- 文章统计:728条
- 文章评论:82条
- QQ群二维码:扫描二维码,互相交流
