您现在的位置是:网站首页 -> 代码相关 文章内容
C/C++ 彻底了解链接器(二)-itarticl.cc-IT技术类文章记录&分享
发布时间: 9年前【代码相关】 264人已围观【返回】
链接器都做了些什么
我们在上文提到过,一个函数或变量的声明,实际上就是在向 C 编译器承诺:这个函数或变已在程序中的别处定义了,而链接器的工作就是兑现这一承诺。根据上文提供的目标文件结构图,现在,我们可以开始着手“填充图中的空白”了。
为了更好地进行说明,我们给之前的 C 文件添个“伴儿”:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | // 初始化的全局变量 intz_global = 11; // 另一个命名为y_global_init的全局变量 , 但它们都是static的 staticinty_global_init = 2; // 声明另一个全局变量 externintx_global_init; intfn_a(intx,inty) { return(x+y); } intmain(intargc,char*argv[]) { constchar*message = "Hello, world"; returnfn_a(11,12); } // 初始化的全局变量 intz_global = 11; // 另一个命名为y_global_init的全局变量 , 但它们都是static的 staticinty_global_init = 2; // 声明另一个全局变量 externintx_global_init; intfn_a(intx,inty) { return(x+y); } intmain(intargc,char*argv[]) { constchar*message = "Hello, world"; returnfn_a(11,12); } |
对象文件原理图
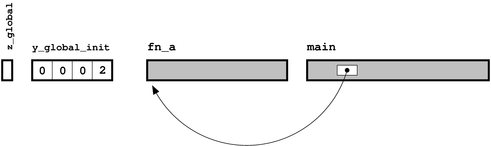
有了这两张图,我们现在可以将这图中所有的节点都互相连通了(如果不能连通,那么链接器在链接过程中就会抛出错误信息)。一切各就各位,如下图所示,链接器可以将空白都填补上了(在Unix系统中,链接器通常由 ld 调用)
对象文件原理图
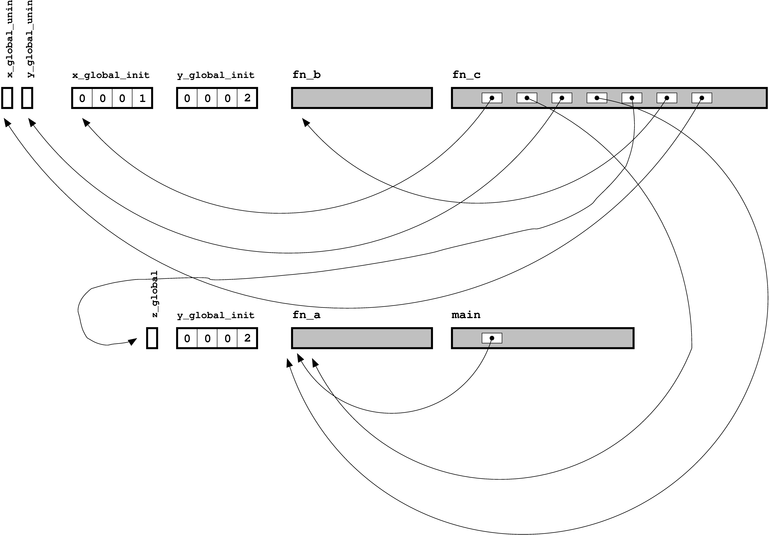
至于目标文件,我们可以使用 nm 命令来检查生成的可执行文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | //samples1.exe中的符号列表: Name Value Class Type Size Line Section _Jv_RegisterClasses | | w | NOTYPE| | |*UND* __gmon_start__ | | w | NOTYPE| | |*UND* __libc_start_main@@GLIBC_2.0| | U | FUNC|000001ad| |*UND* _init |08048254| T | FUNC| | |.init _start |080482c0| T | FUNC| | |.text __do_global_dtors_aux|080482f0| t | FUNC| | |.text frame_dummy |08048320| t | FUNC| | |.text fn_b |08048348| t | FUNC|00000009| |.text fn_c |08048351| T | FUNC|00000055| |.text fn_a |080483a8| T | FUNC|0000000b| |.text main |080483b3| T | FUNC|0000002c| |.text __libc_csu_fini |080483e0| T | FUNC|00000005| |.text __libc_csu_init |080483f0| T | FUNC|00000055| |.text __do_global_ctors_aux|08048450| t | FUNC| | |.text _fini |08048478| T | FUNC| | |.fini _fp_hw |08048494| R | OBJECT|00000004| |.rodata _IO_stdin_used |08048498| R | OBJECT|00000004| |.rodata __FRAME_END__ |080484ac| r | OBJECT| | |.eh_frame __CTOR_LIST__ |080494b0| d | OBJECT| | |.ctors __init_array_end |080494b0| d | NOTYPE| | |.ctors __init_array_start |080494b0| d | NOTYPE| | |.ctors __CTOR_END__ |080494b4| d | OBJECT| | |.ctors __DTOR_LIST__ |080494b8| d | OBJECT| | |.dtors __DTOR_END__ |080494bc| d | OBJECT| | |.dtors __JCR_END__ |080494c0| d | OBJECT| | |.jcr __JCR_LIST__ |080494c0| d | OBJECT| | |.jcr _DYNAMIC |080494c4| d | OBJECT| | |.dynamic _GLOBAL_OFFSET_TABLE_|08049598| d | OBJECT| | |.got.plt __data_start |080495ac| D | NOTYPE| | |.data data_start |080495ac| W | NOTYPE| | |.data __dso_handle |080495b0| D | OBJECT| | |.data p.5826 |080495b4| d | OBJECT| | |.data x_global_init |080495b8| D | OBJECT|00000004| |.data y_global_init |080495bc| d | OBJECT|00000004| |.data z_global |080495c0| D | OBJECT|00000004| |.data y_global_init |080495c4| d | OBJECT|00000004| |.data __bss_start |080495c8| A | NOTYPE| | |*ABS* _edata |080495c8| A | NOTYPE| | |*ABS* completed.5828 |080495c8| b | OBJECT|00000001| |.bss y_global_uninit |080495cc| b | OBJECT|00000004| |.bss x_global_uninit |080495d0| B | OBJECT|00000004| |.bss _end |080495d4| A | NOTYPE| | |*ABS* |
这个表格包含了两个目标文件中的所有符号,显然,之前所有“未定义的引用”都已消失。同时,所有符号都按类型重新排了序,还加入了一些额外的信息以便于操作系统更好地对可执行程序实行统一处理。
输出内容中还有相当多复杂的细节,看上去很混乱,但你只要把以下划线开头的内容都过滤掉,整个结构看上去就简单多了。
重复的符号
上文提到,当链接器试图为某个符号产生连接引用时却找不到这个符号的定义,链接器将抛出错误信息。那么,在链接阶段,如果同一个符号定义了两次又该如何处理呢?
在C++中这种情况很容易处理,因为语言本身定义了一种称为一次定义法则(one definition rule)的约束,即链接阶段,一个符号有且只能定义一次(参见 C++ 标准第3.2章节,这一章节还提及了后文中我们将讲解的一些异常信息)。
对于 C 语言而言,事情就稍稍复杂一些了。C语言明确说明了,对于任何的函数或者已经初始化的全局变量,都有且只能有一次定义,但未初始化的全局变量的定义可以看成是一种临时性定义(a tentative definition)。C 语言允许(至少不禁止)同一个符号在不同的源文件中进行临时性定义。
然而,链接器还得对付除 C/C++ 以外的其它语言,对于那些语言来说,“一次定义法则”并非总是适用。例如,以 Fortran 语言的正态模式(normal model)为例,实际应用中,每个全局变量在其被引用的任何文件中都存在一个复本。此时,链接器需要从多个复本中选择一个(如果大小不同,就选最大的那个),并将剩余复本丢弃。(这种模式有时又称为链接时的“通用模式(common model)”,前头需要加上Fortran关键字: COMMON )
因此,UNIX 系统上的链接器不会为符号的重复定义——或者说不会为未初始化全局变量的重复符号——抛出任何信息,这种情况相当正常(有时,我们将这种情况称为链接时的“松引用/定义模式(relaxed ref/def mode)”模式)。如果你为此感到苦恼(你也完全有理由苦恼),那么你可以查看你所使用的编译器和链接器的相关文档,里面通常会提供一个 –work-properly 选项,用于“收紧”链接器的检测规则。例如,GNU 工具包里提供了 -fno-common 选项,可以让编译器强行将未初始化变量存放于 BSS 段,而不是存于 common 段。
操作系统做了些什么
目前为止,链接器产生了可执行文件,文件中所有符号都与其合适的定义相关联。接下来,我们要休息一会儿,插播一则小知识:当我们运行这个程序时,操作系统都做了些什么?
程序的运行显然需要执行机器代码,因此操作系统无疑需要把硬盘上的可执行文件转换成机器码,并载入内存,这样CPU才能从中读取信息。程序所占用的这块内存,我们称之为代码段(code segment),或者文本段(text segment).
没有数据,再好的代码也出不来——因此,所有全局变量也得一并载入内存。不过已初始化变量和未初始化变量有些不同。初始化变量已经提前赋予了某个特定的初值,这些值同时保存于目标文件和可执行文件中。当程序开始运行时,操作系统将这些值拷贝至内存中一块名为数据段(data segment)的区域。
对未初始化变量,操作系统假设其初值均为0, 因此没有必要对这些值进行拷贝,操作系统保留一部分全为0内存空间,我们称其为 bss 段(bss segment)。
这就意味着可执行文件可以节省这部分存储空间:初始化变量的初始值必须保存于文件中,但对于未初始化变量我们只需要计算出它们占用的空间大小即可。
操作系统如何将可执行文件映射到内存
你可能已经注意到目前我们关于目标文件和链接器的所有讨论都只围绕着全局变量,完全没有作何关于上文提及的局部变量和动态分配内存的介绍。
事实上,这类数据的处理完全无需链接器介入,因为它们的生命周期只存在于程序运行之时——这与链接器进行链接操作还离了十万八千里呢。不过,从文章完整性的角度来考虑,我们还是快速过一下这部分知识点吧:
局部变量被存于内存的“栈”区(stack),栈区的大小随着不同函数的调用和返回而动态地增长或减小。
动态分配的内存而处于另一块空间,我们称之为“堆”(heap),malloc 函数负责跟踪这块空间里还有哪些部分是可用的。
我们将这部分内存空间也添加上,这样,我们就得到了一张完整的程序运行时的内存空间示意图。由于堆和栈在程序运行过程中都会动态地改变大小,通常的处理方式是让栈从一个方向向另一个方向增长,而堆则从另一端增长。也就是说,当二者相遇之时就是程序内存耗尽之日了(到那时,内存空间就被占用得满满当当啦!)。
操作系统如何将可执行文件映射到内存
链接器都做了些什么
现在我们已经对链接器的基础知识有了一定的了解,接下来我们将开始刨根纠底,挖出它更为复杂的细节——大体上,我们会按照链接器每个特性加入的时间顺序来一一介绍。
影响链接器特性的最主要的一个现象是:如果有很多不同的程序都需要做一些相同的操作(例如将输出打印到屏幕上,从硬盘读取文件等),那么显然,一种合理的做法是将这些功能编写成通用的代码,供所有不同的程序使用。
在每个程序的链接阶段去链接相同的目标文件这种方法显然完全可行,但是,想象这么一种方法:把所有相关的目标文件集合都统一存放在一个方便访问的地方——这样我们在使用的时候会觉得生活更加简单美好了~我们将其称为“库”(library)。
(未谈及的技术问题:本节不涉及链接器“重定位(relocation)”这一重要特性的介绍。不同的程序大小也不同,因此,当动态库在不同程序中使用时,将被映射成不同的地址空间,也就是说库中所有的函数和变量在不同的程序中有不同的地址。如果所有访问该地址之处,都使用相对地址(如“向后偏移1020字节”)而不是绝对地址(固定的某个地址值,如 0x102218BF),那这也不是个事儿,可现在我们要考虑的问题在于,现实并不总这么尽如人意,当这种情况出现时,所有绝对地址都必须加上一个合适的偏移量——这就是重定位的概念。由于这一概念对C/C++程序员来说几乎是完全透明的,并且链接中报的错误也几乎不可能由重定位问题导致,因此下文将不会对此赘述。)
静态库
静态库(static library)是“库”最典型的使用方式。前文中提到使用重用目标文件的方法来共享代码,事实上,静态库本质上并不比这复杂多少。
在UNIX系统中,一般使用 ar 命令生成静态库,并以 .a 作为文件扩展名,”lib” 作为文件名前缀,链接时,使用”-l”选项,其后跟着库的名称,用于告诉链接器链接时所需要的库,这时无需加前缀和扩展名(例如,对于名为”libfred.a”的静态库,传递给链接器参数为”-lfred”)。
(过去,为了生成静态库文件,我们还需要使用另一个名为 ranlib 的工具,该工具的作用是在库的起始处建立符号索引信息。如今这一功能已经被整合到 ar 命令中了。)
在Windows平台上,静态库的扩展名为 .LIB,可用 .LIB 工具生成,但由于“导入库”(它只包含了DLL中所需要的基本信息列表,具体介绍可见下文 Windows DLLs也同样使用 .LIB 作为扩展名,因此二者容易产生混淆。
链接器在将所有目标文件集链接到一起的过程中,会为所有当前未解决的符号构建一张“未解决符号表”。当所有显示指定的目标文件都处理完毕时,链接器将到“库”中去寻找“未解决符号表”中剩余的符号。如果未解决的符号在库里其中一个目标文件中定义,那么这个文件将加入链接过程,这跟用户通过命令行显示指定所需目标文件的效果是一样一样的,然后链接器继续工作。
我们需要注意从库中导入文件的粒度问题:如果某个特定符号的定义是必须的,那么包含该符号定义的整个目标文件都要被导入。这就意味着“未解决符号表”会出现长短往复的变化:在新导入的目标文件解决了某个未定义引用的同时,该目标文件自身也包含着其他未定义的引用,这就要求链接器将其加入“符号表”中继续解决。
另一个需要注意的重要细节是库的处理顺序。链接器按命令行从左到右的顺序进行处理,只有前一个库处理结束了,才会继续处理下一个库。换句话说,如果后一个库中导入的目标文件依赖于前一个库中的某个符号,那么链接器将无法进行自动关联。
下面这个例子应该可以帮助大家更好的理解本节内容。我们假设有下列几个目标文件,并且通过命令行向链接器传入:a.o, b.o, -lx, -ly.
文件 a.o b.o libx.a liby.a
目标文件 a.o b.o x1.o x2.o x3.o y1.o y2.o y3.o
定义的变量 a1, a2, a3 b1, b2 x11, x12, x13 x21, x22, x23 x31, x32 y11, y12 y21, y22 y31, y32
未定义的引用 b2, x12 a3, y22 x23, y12 y11 y21 x31
当链接器开始链接过程时,可以解决 a.o 目标文件中的未定义引用 b2,以及 b.o 中的 a3,但 x12 和 y22 仍然处于未定义状态。此时,链接器在第一个库 libx.a 中查找这两个符号,并发现只要将 x1.o 导入,就可以解决 x12 这一未定义引用,但导入 x1.o 同时也不得不引入新的未定义引用:x23 和 y12,因此,此时未定义引用的列表里包含了三个符号:y22, x23, y12。
因为此时链接器还在处理 libx.a,所以就优先处理 x23 了,即从 libx.a 中导入 x2.o,然而这又引入了新的未定义引用——如今列表变成了y22, y12, y11,这几个引用都不在在 libx.a 中,因此链接器开始继续处理下一个库:liby.a。
接下来,同样的处理过程也发生在 liby.a 中,链接器导入 y1.o 和 y2.o:链接器在导入 y1.o 后首先将 y21 加入未定义引用列表中,不过由于 y22 的存在,y2.o 无论如何都必须导入,因此问题就此轻松搞定了。整个复杂的处理过程,目的在于解决所有未定义引用,但只需要将库中部分目标文件加入到最终的可执行文件中,避免导入库中所有目标文件。
需要注意的一点是,如果我们假设 b.o 中也使用了 y32 ,那么情况就有些许不同了。这种情况下,对 libx.a 的链接处理不变,但处理 liby.a 时,y3.o 也将被导入,这将带来一个新问题:又加入了一个新的未定义引用 x31 ,链接失败了——原因在于,链接器已经处理完了 libx.a, 但由于 x3.o 未导入,链接器无法查找到 x31 的定义。
(补充说明:这个例子展示了 libx.a 和 liby.a 这两个库之间出现循环依赖的问题,这是个典型的错误,尤其当它出现Windows系统上时)
共享库
对于像 C 标准库(libc)这类常用库而言,如果用静态库来实现存在一个明显的缺点,即所有可执行程序对同一段代码都有一份拷贝。如果每个可执行文件中都存有一份如 printf, fopen 这类常用函数的拷贝,那将占用相当大的一部分硬盘空间,这完全没有必要。
另一个不那么明显的缺点则是,一旦程序完成静态链接后,代码就永久保持不变了,如果万一有人发现并修复了 printf 中的某个bug,那么所有使用了printf的程序都不得不重新链接才能应用上这个修复。
为了避开所有这些问题,我们引入了共享库(shared libraries),其扩展名在 Unix 系统中为 .so,在 Windows 系统中为 .dll,在Mac OS X系统中为 .dylib。对于这类库而言,通常,链接器没有必要将所有的符号都关联起来,而是贴上一个“我欠你(IOU)”这样的标签,直到程序真正运行时才对贴有这样标签的内容进行处理。
这可以归结为:当链接器发现某个符号的定义在共享库中,那么它不会把这个符号的定义加入到最终生成的可执行文件中,而是将该符号与其对应的库名称记录下来(保存在可执行文件中)。
当程序开始运行时,操作系统会及时地将剩余的链接工作做完以保证程序的正常运行。在 main 函数开始之前,有一个小型的链接器(通常名为 ld.so,译者注[2])将负责检查贴过标签的内容,并完成链接的最后一个步骤:导入库里的代码,并将所有符号都关联在一起。
也就是说,任何一个可执行文件都不包含 printf 函数的代码拷贝,如果 printf 修复了某些 bug,发布了新版本,那么只需要将 libc.so 替换成新版本即可,程序下次运行时,自然会载入更新后的代码。
另外,共享库与静态库还存在一个巨大的差异,即链接的粒度(the granularity of the link)。如果程序中只引用了共享库里的某个符号(比如,只使用了 libc.so 库中的 printf),那么整个共享库都将映射到程序地址空间中,这与静态库的行为完全不同,静态库中只会导入与该符号相关的那个目标文件。
换句话说,共享库在链接器链接结束后,可以自行解决同一个库内不同对象(objects)间符号的相互引用的问题(ar 命令与此不同,对于一个库它会产生多个目标文件)。这里我们可以再一次使用 nm 命令来弄清静态库和共享库的区别:对于前文给出的目标文件和库的例子,对于同一个库,nm 命令只能分别显示每个目标文件的符号清单,但如果将 liby.so 变成共享库,我们只会看到一个未定义符号 x31。同样,上一节提到的由静态库处理顺序引起的问题,将不会共享库中出现:即使 b.o (译者注[3])中使用了 y32,也不会有任何问题,因为 y3.o 和 x3.o 都已全部导入了。
顺便推荐另一个超好用的命令: ldd,该命令是Unix平台上用于显示一个可执行程序(或一个共享库)依赖的共享库,同时还可以显示这些被依赖的共享库是否找得到——为了使程序正常运行,库加载工具需要确保能够找到所有库以及所有的依赖项(一般情况下,库加载工具会在 LD_LIBRARY_PATH 这个环境变量指定的目录列表中去搜寻所需要的库)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | /usr/bin:ldd xeyes linux-gate.so.1 => (0xb7efa000) libXext.so.6 => /usr/lib/libXext.so.6 (0xb7edb000) libXmu.so.6 => /usr/lib/libXmu.so.6 (0xb7ec6000) libXt.so.6 => /usr/lib/libXt.so.6 (0xb7e77000) libX11.so.6 => /usr/lib/libX11.so.6 (0xb7d93000) libSM.so.6 => /usr/lib/libSM.so.6 (0xb7d8b000) libICE.so.6 => /usr/lib/libICE.so.6 (0xb7d74000) libm.so.6 => /lib/libm.so.6 (0xb7d4e000) libc.so.6 => /lib/libc.so.6 (0xb7c05000) libXau.so.6 => /usr/lib/libXau.so.6 (0xb7c01000) libxcb-xlib.so.0 => /usr/lib/libxcb-xlib.so.0 (0xb7bff000) libxcb.so.1 => /usr/lib/libxcb.so.1 (0xb7be8000) libdl.so.2 => /lib/libdl.so.2 (0xb7be4000) /lib/ld-linux.so.2 (0xb7efb000) libXdmcp.so.6 => /usr/lib/libXdmcp.so.6 (0xb7bdf000) /usr/bin:ldd xeyes linux-gate.so.1 => (0xb7efa000) libXext.so.6 => /usr/lib/libXext.so.6 (0xb7edb000) libXmu.so.6 => /usr/lib/libXmu.so.6 (0xb7ec6000) libXt.so.6 => /usr/lib/libXt.so.6 (0xb7e77000) libX11.so.6 => /usr/lib/libX11.so.6 (0xb7d93000) libSM.so.6 => /usr/lib/libSM.so.6 (0xb7d8b000) libICE.so.6 => /usr/lib/libICE.so.6 (0xb7d74000) libm.so.6 => /lib/libm.so.6 (0xb7d4e000) libc.so.6 => /lib/libc.so.6 (0xb7c05000) libXau.so.6 => /usr/lib/libXau.so.6 (0xb7c01000) libxcb-xlib.so.0 => /usr/lib/libxcb-xlib.so.0 (0xb7bff000) libxcb.so.1 => /usr/lib/libxcb.so.1 (0xb7be8000) libdl.so.2 => /lib/libdl.so.2 (0xb7be4000) /lib/ld-linux.so.2 (0xb7efb000) libXdmcp.so.6 => /usr/lib/libXdmcp.so.6 (0xb7bdf000) |
共享库之所以使用更大的链接粒度是因为现代操作系统已经相当聪明了,当你想用静态库的时候,他为了节省一些硬盘空间,就采用小粒度的链接方式,但对于共享库来说,不同的程序运行时共用同一个代码段(但并不共同数据段和 bss 段,因为毕竟不同的程序使用不同的内存空间)。为了做到这一点,必须对整个库的内容进行一次性映射,这样才能保证库内部的符号集中保存在一片连续的空间里——否则,如果某个进程导入了 a.o 和 c.o, 另一个进程导入的是 b.o 和 c.o,那么就没什么共同点可以供操作系统利用了。
发布时间: 9年前【代码相关】264人已围观【返回】【回到顶端】
很赞哦! (1)
上一篇:C/C++ 彻底了解链接器(一)
下一篇:C/C++ 彻底了解链接器(三)
相关文章




点击排行
 单一职责原则、里氏替换原则、依赖倒置原则
单一职责原则、里氏替换原则、依赖倒置原则
站长推荐
 接口隔离原则、迪米特法则、开闭原则
接口隔离原则、迪米特法则、开闭原则







猜你喜欢
站点信息
- 建站时间:2016-04-01
- 文章统计:728条
- 文章评论:82条
- QQ群二维码:扫描二维码,互相交流
