



01unity --24 物理引擎--刚体,碰撞体
什么时候用碰撞体? 物体非背景,要有“阻挡”效果的时候,如墙壁,桌椅,地板等等。
什么时候用刚体? 物体非背景,即有“阻挡”效果,又有物理受力效果。
什么时候使用触发器?物体可以是背景,也可以非背景,强调“接触”效果。如生命球,能拾取的金币等等。

02TCMalloc的使用与源码剖析(安装和使用)
TcMalloc是一个由Google开发的,比glibc的malloc更快的内存管理库。通常情况下ptmalloc2能在300ns执行一个malloc和free对,而TcMalloc能在50ns内执行一个malloc和free对。
TcMalloc可以减少多线程程序之间的锁争用问题,在小对象上能达到零争用。
TcMalloc为每个线程单独分配一个线程本地的Cache,少量的地址分配就直接从Cache中分配,并且定期做垃圾回收,将线程本地Cache中的空闲内存返回给全局控制堆。
TcMalloc认为小于(<=)32K为小对象,大对象直接从全局控制堆上以页(4K)为单位进行分配,也就是说大对象总是页对齐的。
TcMalloc中一个页可以存入一些相同大小的小对象,小对象从本地内存链表中分配,大对象从中心内存堆中分配。

03TCMalloc的使用与源码剖析(申请和归还)
TCMalloc给每个线程分配了一个线程局部缓存,小对象的分配是直接由线程局部缓存来完成的,这样就避免了多线程程序中的锁竞争情况。当线程局部缓存中的内存不够时,会将对象从中央数据结构移动到线程局部缓存中,同时定期的用垃圾收集器把内存从线程局部缓存迁移回中央数据结构中。
TCMalloc将尺寸小于等于256 * 1024字节的对象(“小”对象)和大对象区分开来。大对象直接使用页级分配器从中央页堆直接分配。即,一个大对象总是页对齐的并占据了整数个数的页。

04TCMalloc的使用与源码剖析(内存泄露检查)
gperftools是google提供的一套分析工具,包括堆内存检测heap-profiler,内存泄漏分析工具heap-checker和CPU性能监测工具cpu-profiler。众所周知堆外内存的泄漏是很难追踪的,使用MAT等dump分析工具也只能从堆中最大或者最多的对象入手去分析发生泄漏的地方。而gperftools将malloc的调用替换为它自己的tcmalloc,从而统计所有内存分配的行为,帮助我们更快的定位到发生泄漏的地方。

05记游戏运营之好奇和争执
让游戏用户花钱,出于等价交换,那多半也是满足了用户某方面的需求。当一个人在玩游戏的时候,多半是会把自己代入到游戏中去,一些在现实中无法实现的事情肯定希望在游戏中能实现一二,譬如说希望能当个英雄拯救家园,希望能当个将军驰骋疆场,希望能当个皇帝拥有三千后宫佳丽。譬如还有些用户希望见谁就砍谁一刀来抒发心中的不满,我记得当年玩某个游戏时,正悠闲的走在路上去采药,莫名其妙的就挂了,后发现被路人砍了一刀,然后怒气值直接暴涨。
06帧同步游戏的设计
TCP是基于重传来保证可靠性,如果IP包丢包,TCP协议需要等待至少2个往返时延才会重新发送这个数据包,丢包严重甚至会断线,一旦断线,则触发断线重连流程。
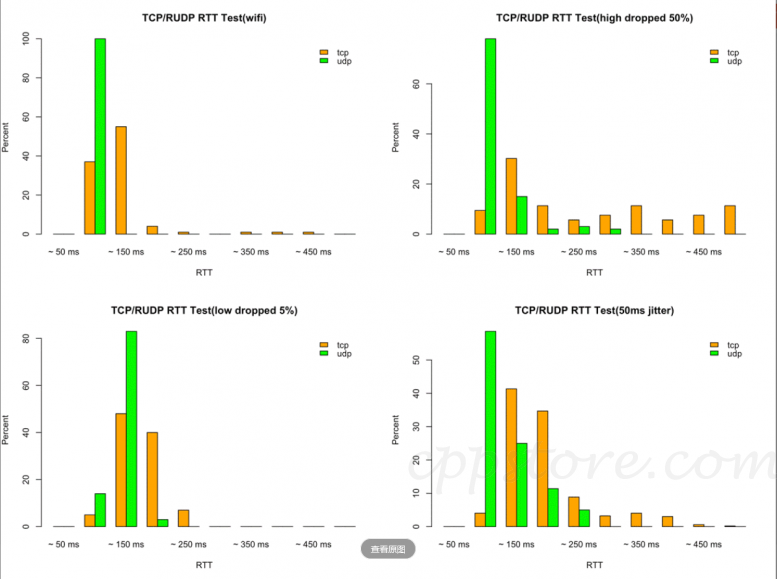
这是腾讯一款以忍者格斗为题材的ACT手游给出来的数据,可以看到在各种网络情形下,UDP的表现(延迟分布)基本上都优于TCP。


07如何计算ARPU和LTV
下面以月ARPU值举例:月总收入 / 月活跃用户数——最传统的定义方法
月总收入 / 月付费用户数——实际上就是ARPPU(Average Revenue Per Paying User):平均每付费用户收入——这样计算会让ARPU值看起来很高,报表很好看。
月总收入 / 累积用户总数——一般不会这么计算,因为存在大量已流失用户和沉默用户,将这部分用户纳入统计是没有意义的。但有时候怕ARPU值太高会有舆论或监管压力,会采用这种计算方法来混淆视听。
月总收入 / 用户分层总数——做数据分析时使用,就是将用户分为不同的类型,总收入也是对应分层用户的总收入。例如可以将用户分为不同渠道来源、是否会员用户、通过使用频次划分等等。可以查看不同渠道来源的用户质量。
不同的定义方法,计算出来的ARPU值差异是很大的。所以给出ARPU值的时候,不给具体计算方法都是耍流氓。

08手游帧同步的要点总结
与状态同步比较
状态同步:状态变化时同步
帧同步:每帧都同步,同步的是帧号和玩家输入;各前端对于同样的输入序列肯定演化成同样的结果
优点
对于前端来说开发效率较高,如同单机游戏,能实现更好的表现效果
流量消耗是稳定的,方便实现录像回放
缺点
网络要求较高
反外挂能力弱
断线重连所需时间长
实现过程
客户端和服务端有完全一样的演算逻辑(排除一切随机因素)
服务端以固定帧频,每帧演算(这里也可以不演算),并将帧号和用户输入同步到客户端
客户端接到服务器数据后,以同样逻辑步进一帧
战斗结束后,以服务端的演算结果为准(也可以不立即验证,而是找服务器空闲时候秋后算账)
实现要点
解决卡顿
使用buffer(可根据延时调整大小)
本地插值平滑
表现与逻辑分离
解决延迟:使用UDP,需要解决丢包问题
一次携带多帧数据,降低丢包率
丢包后客户端重新请求
注意浮点数和随机函数带来的不确定性问题
要有合理的监控机制
对外挂和作弊的监控
对不同步case的监控,有助于发现和修复bug

09Unity3D RTS游戏中帧同步实现
帧同步技术是早期RTS游戏常用的一种同步技术。与状态同步不同的是,帧同步只同步操作,其大部分游戏逻辑都在客户端上实现,服务器主要负责广播和验证操作,有着逻辑直观易实现、数据量少、可重播等优点。
部分PC游戏如帝国时代、魔兽争霸3、星际争霸等,Host(服务器或某客户端)只当接收到所有客户端在某帧输入数据后,才会继续执行,等待直至超时认为该客户端掉线。很明显,当部分客户端因网络或设备问题无法及时上传操作数据,会影响其它客户端的表现,造成不好的游戏体验。考虑到游戏公平竞争性,这种需要等待的机制是必需的,但并不符合手游网络环境的需求。为此,需要使用“乐观”模式,即是Host采集客户端上传操作并按固定频率广播已接收到的操作数据,不在乎部分客户端的操作数据是否上传成功,且不会影响到其它客户端的游戏表现。


10复盘王者荣耀手游开发,Unity引擎使用帧同步放弃状态同步
现在来看,选择帧同步方案之后,我们再把它的缺点进行优化或是规避,之后它带来的好处是非常明显的。《王者荣耀》重除了英雄的设计以及技能的感觉,还有很重要的一点,就是它确实在做一些非常有特色的英雄,它的技能、反馈、体验上面都做得不错,这些都是基于帧同步技术方案带来的优势。
我们选择了方案之后,当时觉得很high,觉得这样一个技术方案开发起来得心应手,效率如此之高,做出来的效果也很好。
但事实上,它也有好的一面,也有坏的一面,技术测试版本上线后质量不好,其中技术层面遇到的问题就是下面这三座大山。
第一是同步性,同步性这块容易解决,其实也解决了;
第二也是最大一块网络问题,帧同步它的网络问题导致我们对它技术方案的原理没有吃透,碰到了一些问题,那时候游戏的延迟很重,画面卡顿,能明显感觉走路抖动的现象;
第三是性能问题,这个问题始终存在,我们也一直在优化。
11lua调用C++函数崩溃时,查看lua的调用栈信息
// 打印lua调用栈开始
lua_getglobal(tolua_S, "debug");
lua_getfield(tolua_S, -1, "traceback");
int iError = lua_pcall( tolua_S, //VMachine
0, //Argument Count
1, //Return Value Count
0 );
const char* sz = lua_tostring(tolua_S, -1);
// 上面的sz里面即为lua的调用栈信息,好好利用吧!

12Lua中ipairs()和pairs()的区别与使用
根据官方手册的描述,pairs会遍历表中所有的key-value值,而pairs会根据key的数值从1开始加1递增遍历对应的table[i]值,直到出现第一个不是按1递增的数值时候退出。
用pairs()遍历是[key]-[value]形式的表是随机的,跟key的哈希值有关系
但是如果是这样定义表stars的话 stars = {"Sun", "Moon", “Earth”, "Mars", "Venus"},表stars是数组的形式,是会按顺序输出的,如果 执行 stars[1] = "day",则数组会变成哈希表,再遍历时就不会顺序输出。



点击排行
 单一职责原则、里氏替换原则、依赖倒置原则
单一职责原则、里氏替换原则、依赖倒置原则
站长推荐
 接口隔离原则、迪米特法则、开闭原则
接口隔离原则、迪米特法则、开闭原则







猜你喜欢
站点信息
- 建站时间:2016-04-01
- 文章统计:728条
- 文章评论:82条
- QQ群二维码:扫描二维码,互相交流
